code

share




The coordinate search and descent algorithms are additional zero order local methods that get around the inherent scaling issues of random local search by restricting the set of search directions to the coordinate axes of the input space. The concept is simple: random search was designed to minimize a function $g\left(w_1,w_2,...,w_N\right)$ with respect to all of its parameters simultaneously. With coordinate wise algorithms we attempt to minimize such a function with respect to one coordinate or weight at a time - or more generally one subset of coordinates or weights at a time - keeping all others fixed.
While this limits the diversity of descent directions that can be potentially discovered, and thus more steps are often required to determine approximate minima, these algorithms are far more scalable than random search (so much so that they can indeed be effectively used in practice with even medium sized machine learning problems). Additionally - as was the case with the random search approach - these algorithms serve as predicates for an entire thread of higher order coordinate descent methods we will see in the next few Chapters. Through understanding coordinate search / descent in the comparatively simpler zero order framework we are currently in we lay the ground work for better understanding of this entire suite of powerful coordinate-based algorithms.
The coordinate search algorithm takes the theme of descent direction search and - instead of searching randomly - restricts the set of directions to the coordinate axes of the input space alone. While this significantly limits the kinds of descent directions we can recover it far more scalable than seeking out a good descent direction at random, and opens the search-approach to determining descent directions to usage with higher dimensional input functions.
As illustrated in the Figure below for an $N$ = 2 dimensional example, with coordinate search we seek out the best descent direction among only the coordinate axes of the input space. This means in general that for a function of input dimension $N$ we only look over $2N$ directions - the positive and negative versions of each coordinate input. As with the random local search algorithm we will use unit-length directions, meaning that at every step the set of directions we search over always consists of just positive and negative versions of the standard basis.
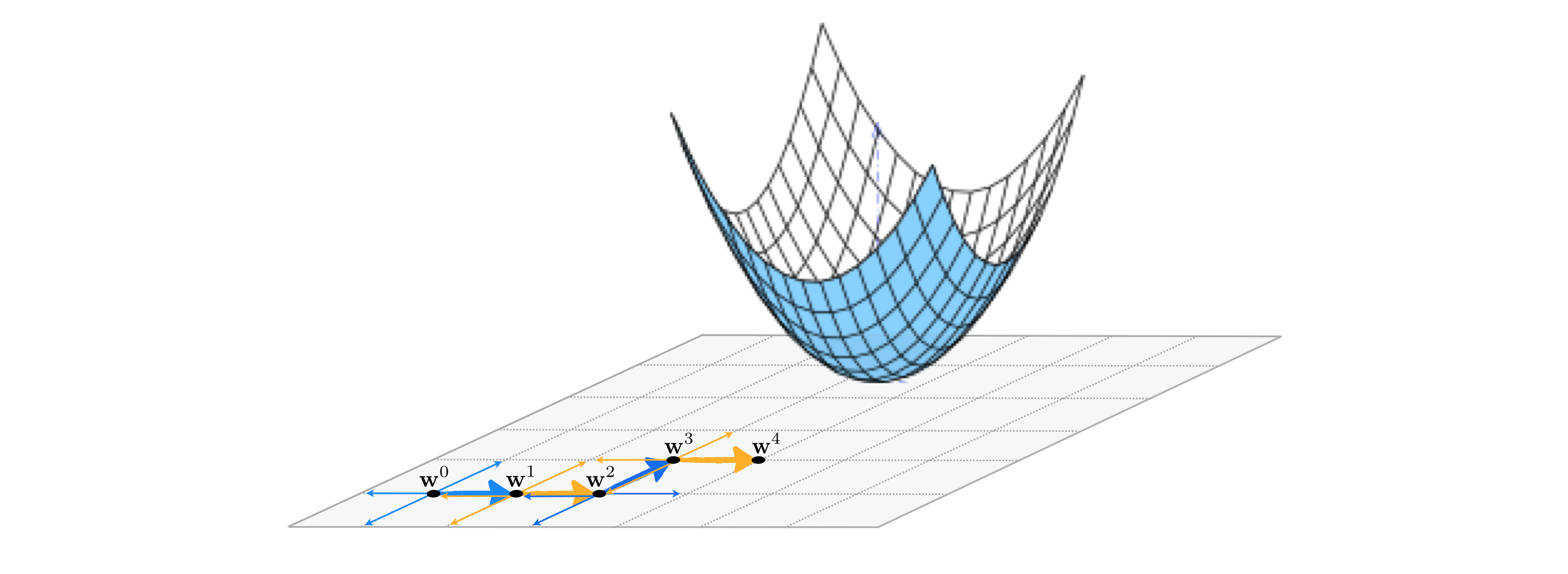
In an $N$ dimensional input space the $n^{th}$ standard basis vector - denoted $\mathbf{e}_n$ - is just a vector of all zeros whose $n^{th}$ entry is set to $1$. Searching only over the positive and negative set of these directions means at the $k^{th}$ step of this local method we search only over the set of $2N$ candidate directions $\left\{\pm \, \mathbf{e}_n \right\}_{n=1}^N$ for the best descent direction (if one exists). This means - in particular - each pair of candidate points using a single standard basis direction looks like
\begin{equation} \mathbf{w}_{\text{candidate}} = \mathbf{w}^{k-1} \pm \alpha \mathbf{e}_n. \end{equation}
It is this restricted set of directions we are searching over that distinguishes the coordinate search approach from the random search approach described in the previous Section, where the set of directions at each step was made up of random directions. While the diversity of the coordinate axes may limit the effectiveness of the possible descent directions it can encounter and thus require more steps to determine an approximate minimum, the restricted search makes coordinate search far more scalable than the random search method since at each step only $2N$ directions must be tested.
A slight twist on the coordinate search produces a much more effective algorithm at precisely the same computational cost. Instead of collecting each coordinate direction (along with its negative), and then choosing a single best direction from this entire set, we can simply examine one coordinate direction (and its negative) at a time and step in this direction if it produces descent. Whereas with coordinate search we evaluate the cost function $2N$ times (once per coordinate direction and its negative) to produce a single step, this alternative takes the same number of function evaluations but potentially moves $N$ steps in doing so. In other words this means that for precisely the same cost as coordinate search we can (potentially) descent much faster with coordinate descent.
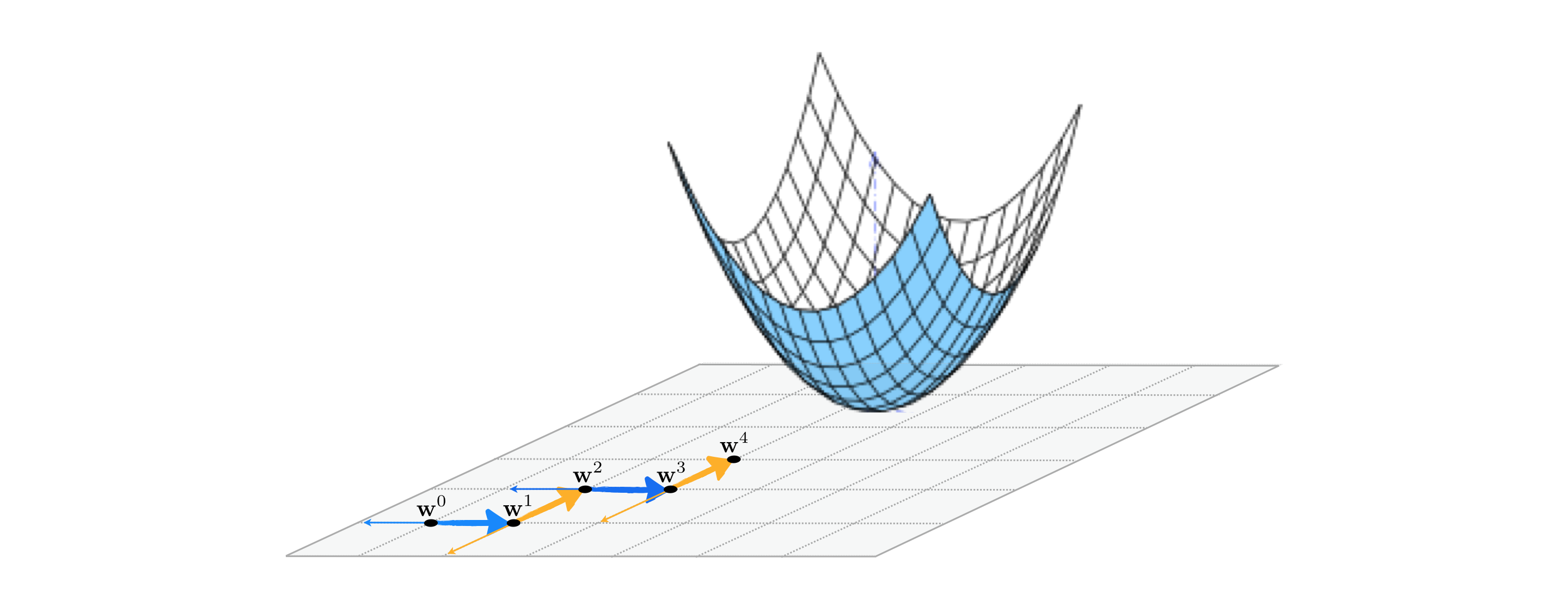
This twist on the coordinate search approach is called a coordinate descent, since each step evaluates a single coordinate direction and decides whether or not to move in this direction alone. This particular algorithm - while itself being the most effective zero order method we have seen thus far by far - is a predicate for many useful coordinate descent approaches we will see in future Chapters as well.
In this example we compare the efficacy of coordinate search and the coordinate descent algorithm described above using the same function from the previous example. Here we compare $20$ steps of coordinate search (left panel) and coordinate descent (right panel), using a diminishing step length for both runs. Because coordinate descent takes two steps for every single step taken by coordinate search we get significantly closer to the function minimum.

We can view the precise difference more easily by comparing the two function evaluation histories via the cost function history plot, which we do below. Here we can see in this instance while the first several steps of coordinate search were more effective than their descent counterparts (since they search over the entire list of coordinate directions instead of one at a time), the coordinate descent method quickly overtakes search finding a lower point on the cost function.


While the directions used by coordinate search are far simpler than those we can potentially find by randomly search, we can often find a descent direction among them that works well enough. Moreover coordinate search is far more efficient per step than its random counterpart, requiring $2N$ function evaluations per step as compared to a number of random sample directions $P$ which - as we saw in the previous Section - must grow exponentially in $N$ in order for random search to be truly effective. This is a considerable gain in efficiency, but as we will see starting in the next Chapter we can do even better, much better in fact.