code

share




The standard regularization procedure for cross-validation presented in Section 11.4 requires many complete minimizations of the given cost function in order to determine the optimal setting of model weights. However optimization of neural networks (particularly those employing many hidden layers) can be challenging and computationally intensive, making cross-validation via the typical regularization approach very difficult. In this Section we introduce an alternative regularization technique called early stopping that is commonly used with neural network models. Early stopping presents a comparatively cheap alternative for regularizing network models, where optimal parameters are chosen from a single optimization run by halting it when validation error is at its lowest.
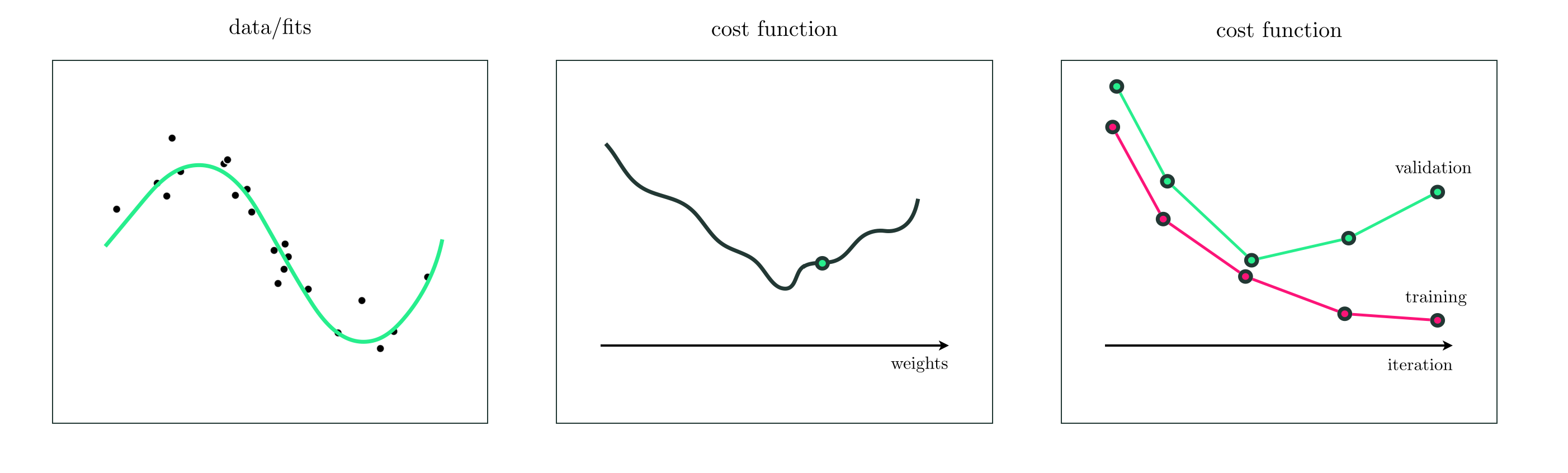
With any technique for cross-validation (introduced in Section 11.2) our ideal is to find a model that provides the lowest possible error on a validation set. With early stopping we do this by stopping the minimization of a cost function (which is measuring training error) when validation error reaches its lowest point. The basic idea is illustrated in the figure below. In the left panel we show a prototypical nonlinear regression dataset, and in the middle the cost function of a high capacity model (like a deep neural network) shown figuratively in two dimensions. As we begin a run of a local optimization method we measure both the training error (provided by the cost function we are minimizing) as well as validation error at each step of the procedure, as shown in the right panel. We try to halt the procedure when the validation error has reached its lowest point. This regularization technique is commonly used as a cheap alternative to the standard approach outlined in Section 11.4, particularly with deep neural network models that can be difficult to optimize, as it requires only a single optimization run.
There are a number of important engineering details associated with making an effective early stopping procedure. These include
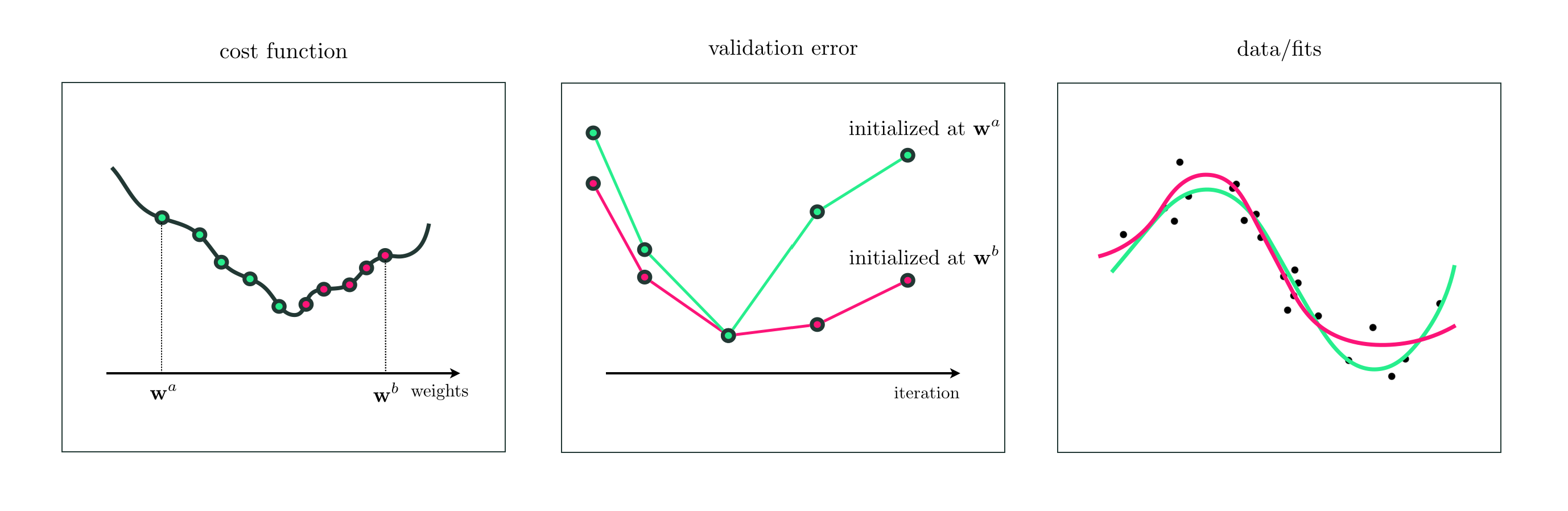
Notice that because we are stopping our optimization procedure early based on validation error, that different weights (and correspondingly different shape nonlinearities) can be found via early stopping depending on the initialization of the local method used and the trajectory of the optimization. This is illustrated pictorally in the figure below.
Below we show a few examples employing the early stopping regularization strategy.
Below we illustrate the early stopping procedure using a simple nonlinear regression dataset (split into $\frac{2}{3}$ training and $\frac{1}{3}$ validation), and a (artbitrarily chosen) three hidden layer network with $10$ units per layer and the $\text{tanh}$ activation. A single run of gradient descent is illustrated below, as you move the slider left to right you can see the resulting fit at each highlighted step of the run in the original dataset (top left), training (bottom left), and validation data (bottom right). Moving the slider to where the validation error is lowest provides - for this training / validation split of the original data - a fine nonlinear model for the entire dataset.
Below we plot a prototypical nonlinear classification dataset. We will use early stopping regularization to fine tune the capacity of a model consisting of $5$ single hidden layer tanh neural network universal approximators.
Below we illustrate a large number of gradient descent steps to tune our high capacity model for this dataset. As you move the slider left to right you can see the resulting fit at each highlighted step of the run in the original dataset (top left), training (bottom left), and validation data (bottom right). Moving the slider to where the validation error is lowest provides - for this training / validation split of the original data - a fine nonlinear model for the entire dataset.
In this example we illustrate the result of early stopping using a subset of $P = 10,000$ points from the MNIST dataset, employing (an arbitrarily chosen) three hidden-layer architecture with $10$ units per layer and the relu activation function. Here we employ $80\%$ of the dataset for training and the remainder for validation, and run gradient descent for $3,000$ steps measuring the cost function and number of misclassifications at each stsp over both training and validation sets.
The cost function over the validation error reaches a minimum value around step $1,000$, and the misclassifications over validation reaches a mininum of $230$ around step $1,5000$.
