code

share




In Chapter 10 we saw how supervised and unsupervised learners alike can be extended to perform nonlinear learning via the use of nonlinear functions (or feature transformations) that we engineered ourselves by visually examining data. For example, we expressed a general nonlinear model for regression and two-class classification as a weighted sum of $B$ nonlinear functions of our input as
\begin{equation} \text{model}\left(\mathbf{x},\Theta\right) = w_0 + f_1\left(\mathbf{x}\right){w}_{1} + f_2\left(\mathbf{x}\right){w}_{2} + \cdots + f_B\left(\mathbf{x}\right)w_B \label{equation:general-model-chapter-11-intro} \end{equation}
where $f_1$ through $f_B$ are nonlinear parameterized or unparameterized functions (or features) of the data, and $w_0$ through $w_B$ (along with any additional weights internal to the nonlinear functions) are represented in the weight set $\Theta$.
In this Chapter we detail the fundamental tools and principles of feature learning (or automatic feature engineering) that allow us to automate this task and learn proper features from the data itself, instead of \emph{engineering} them ourselves. In particular we discuss how to choose the form of the nonlinear transformations $f_1$ through $f_B$, the number $B$ of them employed, as well as, how the parameters in $\Theta$ are tuned, automatically and for any dataset.
As we have described in previous Chapters, features are those defining characteristics of a given dataset that allow for optimal learning. In Chapter 10 we saw how the quality of the mathematical features we can design ourselves is fundamentally dependent on our level of knowledge regarding the phenomenon we were studying. The more we understand (both intellectually and intuitively) the process generating the data we have at our fingertips, the better we can design features ourselves. At one extreme where we have near perfect understanding of the process generating our data, this knowledge having come from considerable intuitive, experimental, and mathematical reflection, the features we design allow near perfect performance. However, more often than not we know only a few facts, or perhaps none at all, about the data we are analyzing. The universe is an enormous and complicated place, and we have a solid understanding only of how a sliver of it all works.
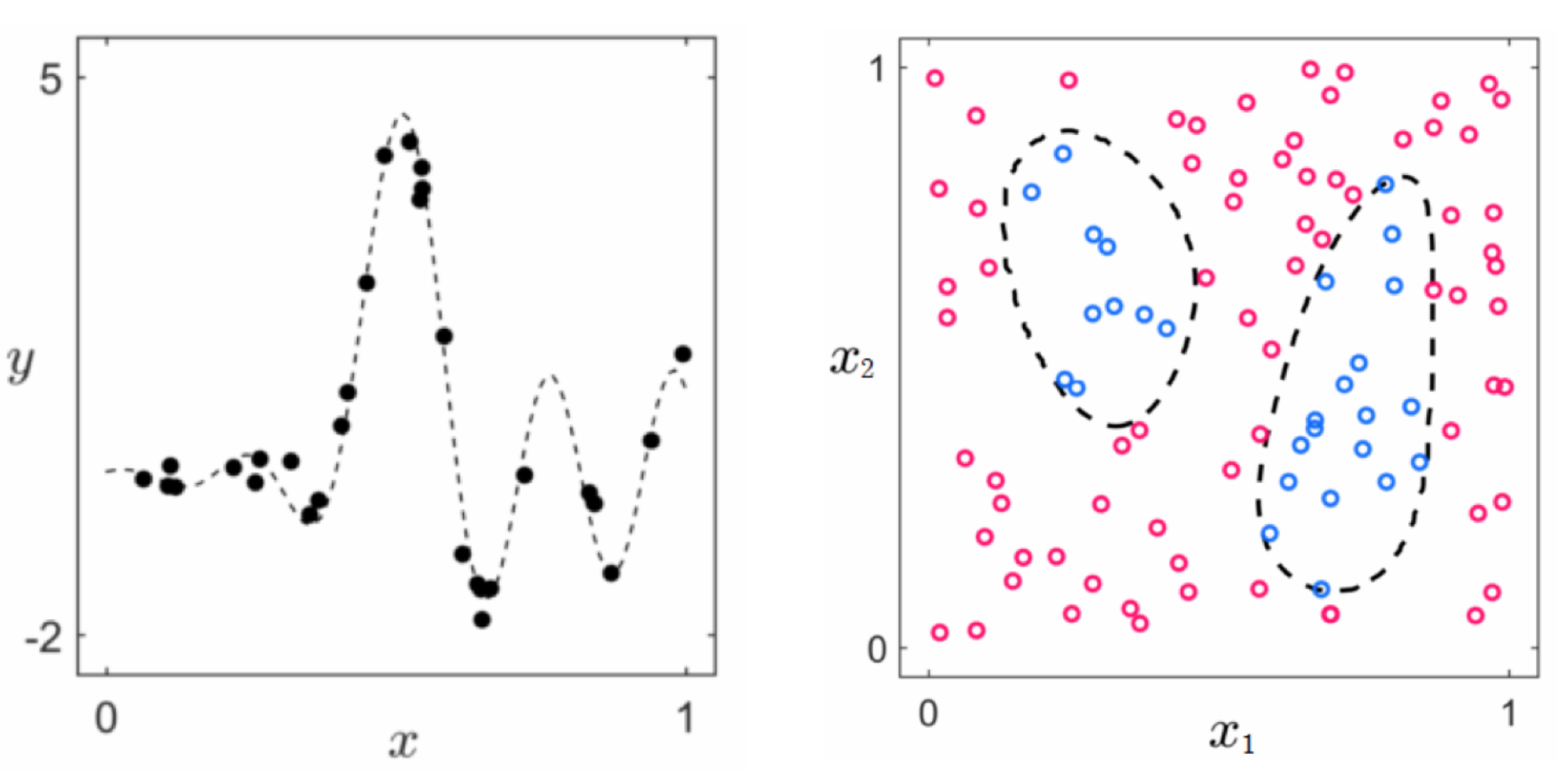
Most (particularly modern) machine learning datasets have far more than two inputs, rendering visualization useless as a tool for feature engineering. But even in rare cases where data visualization is possible, we cannot simply rely on our own pattern recognition skills. Take the two toy datasets illustrated in Figure 11.1 below, for example. The dataset on the left is a regression dataset with $N=1$ dimensional input and the one on the right is a two-class classification dataset with $N=2$ dimensional input. The true underlying nonlinear model used to generate the data in each case is shown in dashed black. We humans are typically taught only how to recognize the simplest of nonlinear patterns by eye, including those created by elementary functions (e.g., low degree polynomials, exponential functions, sine waves) and simple shapes (e.g., squares, circles, ellipses). Neither of the patterns shown in the Figure match such simple nonlinear functionalities. Thus, whether or not a dataset can be visualized, human engineering of proper nonlinear features can be difficult if not outright impossible.
It is precisely this challenge which motivates the fundamental feature learning tools described in this Chapter. In short, these technologies automate the process of identifying appropriate nonlinear features for arbitrary datasets. With these tools in hand we no longer need to engineer proper nonlinearities, at least in terms of how we engineered nonlinear features in the previous Chapter. Instead, we aim at learning their appropriate forms. Compared to our own limited nonlinear pattern recognition abilities, feature learning tools can identify virtually any nonlinear pattern present in a dataset regardless of its input dimension.
The aim to automate nonlinear learning is an ambitious one and perhaps at first glance an intimidating one as well, for there are an infinite variety of nonlinearities and nonlinear functions to choose from. How do we, in general, parse this infinitude automatically to determine the appropriate nonlinearity for a given dataset?
The first step, as we will see in Section 11.2, is to organize the pursuit of automation by first placing the fundamental building blocks of this infinitude into manageable collections of (relatively simple) nonlinear functions. These collections are often called universal approximators, of which three strains are popularly used and which we introduce here: fixed-shape approximators, artificial neural networks, and trees. After introducing universal approximators we then discuss the fundamental concepts underlying how they are employed, including the necessity for validation error as a measurement tool in Section 11.3, a description of cross-validation and the bias-variance tradeoff in Section 11.4, the automatic tuning of nonlinear complexity via boosting and regularization in Sections 11.5 and 11.6, respectively, as well as the notion of ensembling or bagging in Section 11.9 and K-folds cross-validation in Section 11.10.
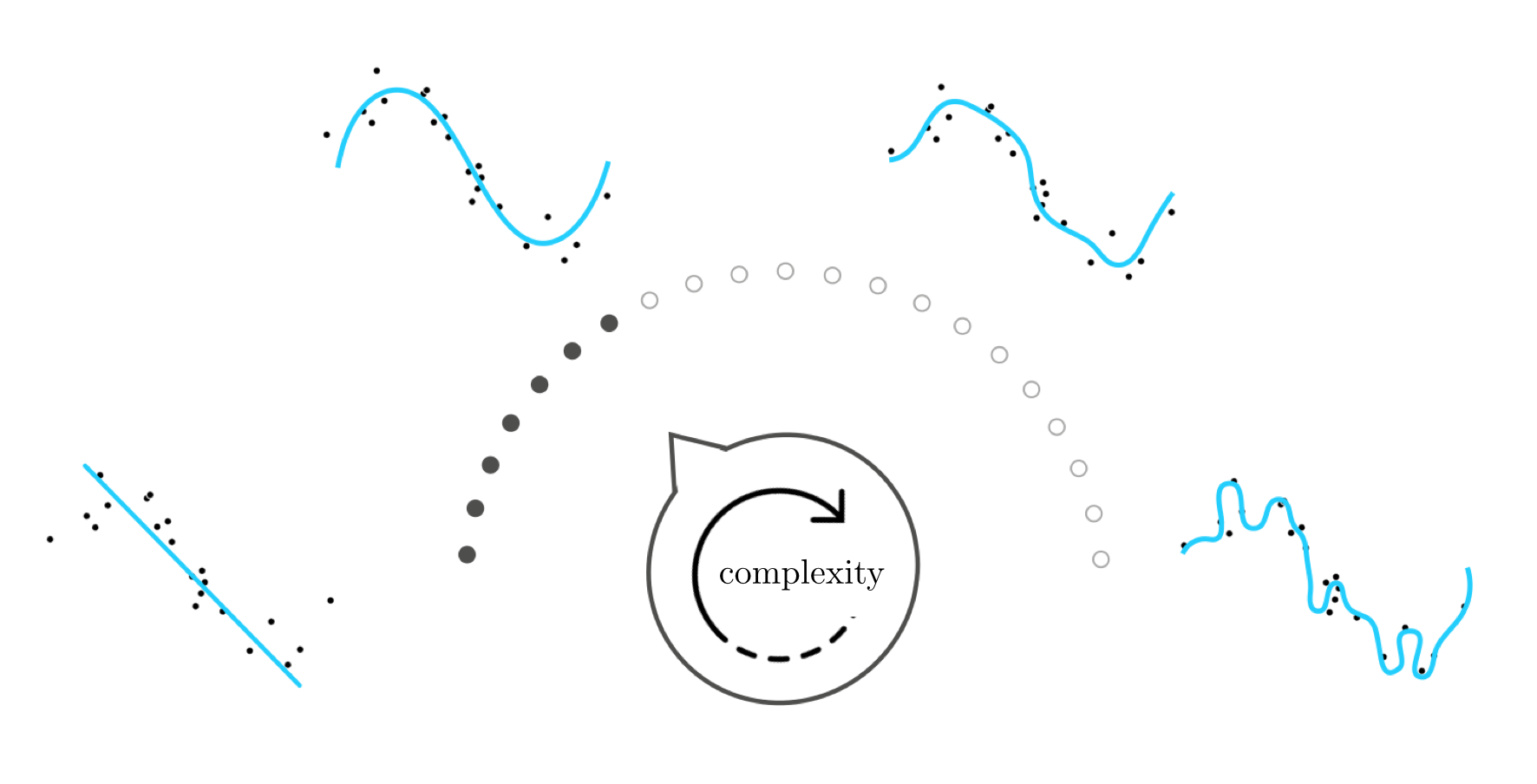
The ultimate aim of feature learning is a paradigm for the appropriate and automatic learning of features for any \emph{any dataset} regardless of problem type. This translates - formally speaking - into the the automatic determination of both the proper form of the general nonlinear model in Equation (1) above and the proper parameter tuning of this model regardless of training data and problem type. We can think about this challenge metaphorically as 1) the construction of and 2) the automatic setting of a complexity dial, like the one illustrated pictorially in Figure 11.2 for a simple nonlinear regression dataset, that allows us to properly learn the appropriate features for any dataset regardless of problem type. In other words, the 'complexity dial' conceptualization of feature learning visually depicts the challenge of feature learning at a high level as a dial that must be built and automatically tuned to determine the appropriate amount of model complexity needed to represent the phenomenon generating a generic training dataset.
Setting this complexity dial all the way to the left corresponds, generally speaking, to choosing a simple form for the nonlinear model that results in a representation of low complexity (e.g., a linear model, as depicted visually in the Figure). As the dial is turned from left to right various models of increasing complexity are tried against the training data. If turned too far to the right the resulting model will be too complex (or too 'wiggly') with respect to the training data (as depicted visually in the two small panels on the right side of the dial). When set 'just right' (as depicted visually in the small image atop the complexity dial that is second to the left) the resulting model represents the data - as the underlying phenomenon generating it - very well.
While the complexity dial is a simplified depiction of feature learning we will see that it is nonetheless a helpful metaphor, as it will help us organize our understanding of the diverse set of ideas involved in performing it properly.