code

share




In this Section we present a description of nonlinear feature engineering for multi-class classification first introduced Chapter 7. This mirrors what we have seen in the previous Section completely with one small but important difference: in the multi-class case we can choose to model each two-class subproblem seperately (i.e., One-versus-All multi-class classification), employing one nonlinear model per two-class subproblem, or perform multi-class classification jointly producing a single global nonlinear model whose parameters we tune simultaenously.
Recall that when dealing withi mulit-class classification (see Chapter 7) we have $N$ input/output pairs $\left(\mathbf{x}_p,\,y_p\right)$ where by default our label values lie in the set $y_p \in \left\{0,1,...,C-1\right\}$ (however note, as detailed in Section 7.3, we can indeed use any label values we wish), and our joint linear model for all $C$ clas (as first detailed in Section 7.1.7) takes the form
\begin{equation} \text{model}\left(\mathbf{x},\mathbf{W}\right) = \mathring{\mathbf{x}}^T\mathbf{W}^{\,} \end{equation}
where the weight matrix $\mathbf{W}$ has dimension $\left(N+1\right)\times C$. Notice that - as was pointed out in Sections 7.2 and 7.3 - this is precisely the same linear model used with multi-output regression. We can safely wager that the nonlinear extension of multi-class classification takes a similar form to that discussed for multi-output regression as detailed in Section 10.2 (and we would win this wager since - as we will see - this assertion is indeed correct).
With the parameters of this matrix fixed we make predictions based on the fusion rule
\begin{equation} y = \underset{c=0,..,C-1}{\text{argmax}}\,\,\mathring{\mathbf{x}}^T\mathbf{w}_c^{\,}. \end{equation}
where $\mathbf{w}_c$ is the $c^{th}$ column of $\mathbf{W}$.
As discussed in Chapter 7 we can tune the parameters of this joint model one column at a time by solving a sequence of $C$ two-class subproblems independently - this is the One-versus-All approach detailed in Section 7.2. We can also tune the parameters of $\mathbf{W}$ simultaneously by minimizing an appropriate multi-class cost function over the entire matrix at once using e.g., the Multiclass Softmax / Cross-Entropy cost detailed in Section 7.3
\begin{equation} g\left(\mathbf{W}\right) = \frac{1}{P}\sum_{p = 1}^P \left[\text{log}\left( \sum_{c = 0}^{C-1} e^{ \mathring{\mathbf{x}}_{p}^T \overset{\,}{\mathbf{w}}_c^{\,}} \right) - \mathring{\mathbf{x}}_{p}^T \overset{\,}{\mathbf{w}}_{y_p}^{\,}\right] \end{equation}
and unlike the case of multi-output regression these two approaches lead to similar but not exactly equivalent results.
Similar to the linear case, in general we have two main avenues for moving to nonlinear multi-class classification: we can either employ a One-versus-All approach and use precisely the framework for nonlinear two-class classification introduced in the previous Section with each of our $C$ two-class subproblems, or we can introduced nonlinearity jointly across all $C$ classifiers and tune all parameters simultaneously. These are the same two choices we saw with nonlinear multi-output regression in Section 10.3.
If we choose the former approach - forming $C$ distinct nonlinear models - each feature engineering / noonlinear two-class classification is executed precisely as we have seen in previous the Section. We can also, on the other hand, tune the parameters of these $C$ distinct nonlinear models simultaneously by minimizing an appropriate cost function like e.g., the Multiclass Softmax.
On the other hand, if we choose a single set of features for all $C$ of our models we can express the $c^{th}$ of which compactly as
\begin{equation} \text{model}_c\left(\mathbf{x},\Theta_c\right) = \mathring{\mathbf{f}}_{\,}^T \mathbf{w}_c \end{equation}
employing the compact notation $\mathring{\mathbf{f}}_{\,}$ used in the previous Section to compactly denote our $B$ feature transformations, and denoting $\Theta_c$ as the linear combination weights and $\Theta_c$ the entire set of parameters (incuding any parameters internal to the feature transformations) for this classification. As mentioned in Section 10.3.2, using the same feature transformation for each model is often done to simplify the chores of nonlinear feature engineering and - as we will see - nonlinear feature learning.
Once each model has been tuned properly we predict the label of an input point $\mathbf{x}$ employing the fusion rule across all $C$ of these nonlinear models - mirroring our approach in the linear setting
\begin{equation} y = \underset{c=0,..,C-1}{\text{argmax}}\,\,\mathring{\mathbf{f}}_{\,}^T \mathbf{w}_c. \end{equation}
Precisely as with multi-output regression detailed in Section 10.3.2 we can combine these $C$ models together (using precisely the same notation employed there) as
\begin{equation} \text{model}\left(\mathbf{x},\Theta\right) = \mathring{\mathbf{f}}_{\,}^T \mathbf{W} \end{equation}
where note in particular here $\Theta$ contains the parameters of all $C$ individual models.
To properly tune the parameters here we must minimize an appropriate cost like e.g., the Multiclass Softmax
\begin{equation} g\left(\Theta\right) = \frac{1}{P}\sum_{p = 1}^P \left[\text{log}\left( \sum_{c = 0}^{C-1} e^{ \mathring{\mathbf{f}}_{p}^T \overset{\,}{\mathbf{w}}_c^{\,}} \right) - \mathring{\mathbf{f}}_{p}^T \overset{\,}{\mathbf{w}}_{y_p}^{\,}\right] \end{equation}
Given the additional number of models here determining features by visual analysis is more challenging than the basic instance of two-class classification detailed in the previous Section. Here we provide a simple example of this sort of feature engineering.
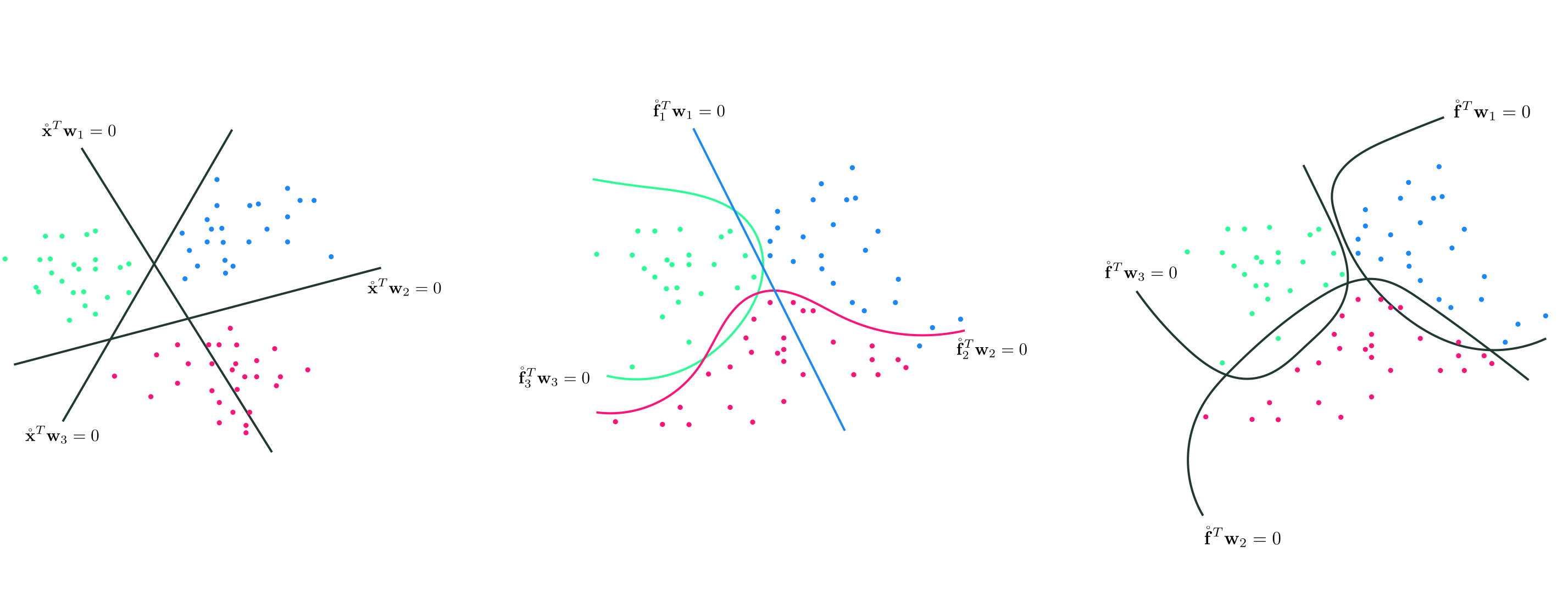
In this example we use perform One-versus-All multiclass classification on the dataset shown below, which consists of $C=3$ classes that appear to be separable by elliptical boundaries.

While it looks like the classes of this dataset can be cleanly separated via elliptical boundaries, the distribution of each class is not centered at the origin. This means that, in order to properly determine these elliptical boundaries, we cannot just use pure quadratic terms in each input dimension. Here to capture this behavior we will use a full degree 2 polynomial expansion of the input. Terms from a general degree $D$ polynomial always take the form
\begin{equation} f\left(\mathbf{x}\right) = x_1^ix_2^j \end{equation}
where $i + j \leq D$. To employ all of them for $D = 2$ means using the following nonlinear model
\begin{equation} \text{model}\left(\mathbf{x},\Theta\right) = w_0 + x_1w_1 + x_2w_2 + x_1x_2w_3 + x_1^2w_4 + x_2^2w_5 \end{equation}
where each term in usage (besides the bias $w_0$) is an unparameterized feature transformation.
After standard-normalzing the input, we solve each of the $C$ two class problems (via minimizing the Softmax cost) employing the feature transformation above using $1,500$ gradient descent steps, $\alpha = 1$ for each run, and the same random initialization for each run. Now we plot each resulting two-class classifier (top row below), as well as the combined results determined by the fusion rule both from a regression perspective (bottom left panel) and from 'above' (in the right panel). Here we were able to achieve perfect classification.

Now we repeat the same experiment on the same dataset, as well as the same set of polynomial feature transformations, but now use the Multiclass Softmax cost function to perform classification simultaneously. We tune all parameters of the model simultaneously via gradient descent and - as shown below - achieve just as solid results as when using the nonlinear One-versus-All framework.

Python¶The general nonlinear model in equation (7) above can be implemented precisely as described in Section 10.2.4. since - indeed - it is the same general nonlineaer model we use with nonlinear multi-output regression. Therefore, just as with multi-output regression, the we need not alter the implementation of a joint nonlinear multi-class classification cost function introduced in Chapter 7 to perform classification: all we need to do is properly define our nonlinear transformation(s) in Python (if we wish to use an automatic differentiator then these should be expressed using autograd's numpy wrapper).