code

share




In this Section we introduce the general framework of nonlinear classification, along with a number of elementary examples. These examples are all low dimensional, allowing us to visually examine patterns in the data and propose appropriate nonlinearities, which we can (as we will see) very quickly inject into our linear supervised paradigm to produce nonlinear classifications. As in the prior Sections, in doing we are performing nonlinear feature engineering for the two-class classification paradigm. Just as with the previous Section by walking through these examples we flush out a number important concepts in concrete terms, coding principles, and jargon-terms in a relatively simple environment that will be omnipresent in our discussion of nonlinear learning going forward.
While we employed a linear model in deriving linear two-class classification in Chapter 6, this linearity was simply an assumption about the sort of boundary that (in general) largely distinguishe two classes of data. Our assumption of a linear boundary translates precisely to the linear model
\begin{equation} \text{model}\left(\mathbf{x},\mathbf{w}\right) = \mathring{\mathbf{x}}_{\,}^T\mathbf{w}^{\,} \end{equation}
where here we use the same compact notation here as in e.g., Section 10.2.1. Our linear decision boundary - employing by default label values $y_p \in \left\{-1,+1\right\}$ - then lies precisely where this formula (for a fixed set of parameters) for input $\mathbf{x}$ where $\mathring{\mathbf{x}}_{\,}^T\mathbf{w}^{\,} = 0$ and label predictions are made (see Section 6.3) as
\begin{equation} y = \text{sign}\left(\mathring{\mathbf{x}}_{\,}^T\mathbf{w}^{\,}\right). \end{equation}
To tune the set of weights properly for a given dataset we must minimize a proper two-class classification cost function like e.g., the Softmax / Cross-Entropy
\begin{equation} g\left(\mathbf{w}\right) = \frac{1}{P}\sum_{p=1}^{P} \text{log}\left(1 + e^{-y_p \mathring{\mathbf{x}}_{p}^T \mathbf{w}}\right). \end{equation}
However like the linear assumption made with regression, this was simply an assumption - we can just as easily assume nonlinear models / decision boundaries and derive precisely the same cost functions we arrived at there. In other words while we employed a linear model throughout Chapter 6 in deriving two-class classification schemes we could have just as well use any nonlinear model of the general form we have employed throughout this Chapter
\begin{equation} \text{model}\left(\mathbf{x},\Theta\right) = w_0 + f_1\left(\mathbf{x}\right){w}_{1} + f_2\left(\mathbf{x}\right){w}_{2} + \cdots + f_B\left(\mathbf{x}\right)w_B \end{equation}
where $f_1,\,f_2,\,...\,f_B$ are nonlinear parameterized or unparameterized functions - or feature transformations - and $w_0$ through $w_B$ (along with any additional weights internal to the nonlinear functions) are represented in the weight set $\Theta$ and must be tuned properly. We can express this - using the same compact notation introduced in 10.1.2 - equivalently as
\begin{equation} \text{model}\left(\mathbf{x},\Theta\right) = \mathring{\mathbf{f}}_{\,}^T \mathbf{w}. \end{equation}
In complete analogy to the linear case, here our decision boundary consists of all inputs $\mathbf{x}$ where $\mathring{\mathbf{f}}_{\,}^T \mathbf{w} = 0$ and likewise predictions are made as
\begin{equation} y = \text{sign}\left(\mathring{\mathbf{f}}_{\,}^T \mathbf{w}\right). \end{equation}
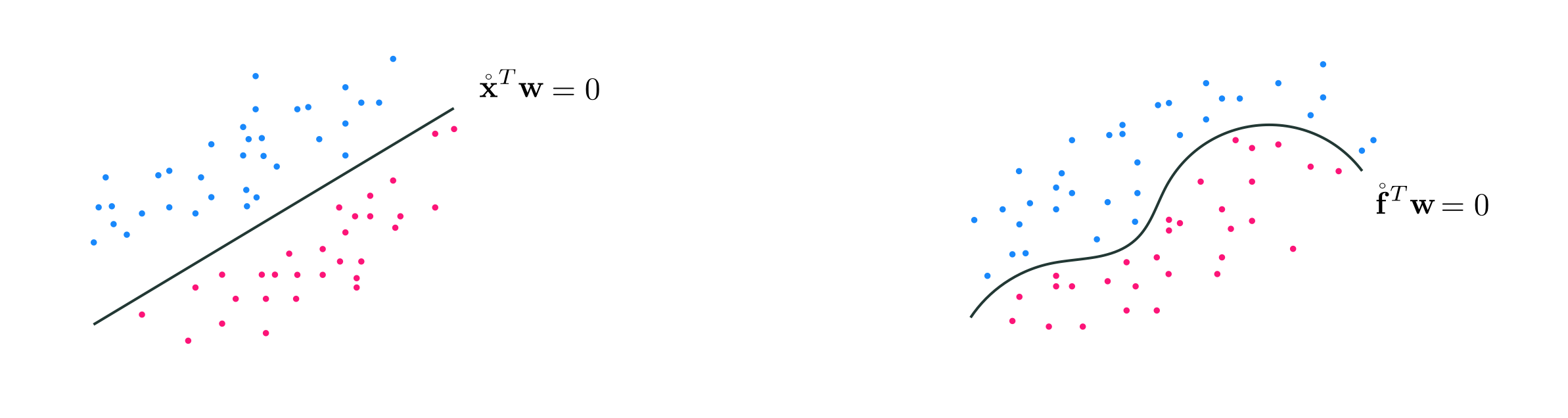
Likewise to properly tune the paramters of $\Theta$ we must minimize a proper cost function with respect to it, like e.g., the Softmax cost
\begin{equation} g\left(\Theta\right) = \frac{1}{P}\sum_{p=1}^{P} \text{log}\left(1 + e^{-y_p \mathring{\mathbf{f}}_{p}^T \mathbf{w}}\right). \end{equation}
In rare cases like e.g., for some low-dimensional datasets we can fairly easily engineer a proper set of nonlinear features for two-class classification 'by eye', that is by examining a dataset visually. Below we explore several such examples.
To start lets re-examine the basic instance of linear classification through the lens of feature engineering. Below we load in a simple single input dataset two class dataset with label values that is linearly separable (with only one input dimension this that the two classes are perfectly separable by linear decision boundary that is just a point).

Here we would use our standard linear model
\begin{equation} \text{model}\left(x,\mathbf{w}_{\!}\right) = w_0 + xw_1. \end{equation}
Although we did not explicitly call it such until this Chapter, here we are employing the simple linear feature transformation
\begin{equation} f\left(x\right) = x \end{equation}
and in this notation our model is then equivalently
\begin{equation} \text{model}\left(x,\Theta\right) = w_0 + f\left(x\right)w_{1\,}. \end{equation}
Note here that the weight set $\Omega = \left\{\mathbf{w}\right\}$.
Below we perform a run of gradient descent to minimize the Softmax cost on this dataset - first performing standard normalization on the input as detailed in Section 9.3. This means (as detailed in the previous Section as well) that we can actually think of the normalization as being a part of the feature transformation itself, and write it formally as
\begin{equation} f\left(x \right) = \frac{x - \mu}{\sigma} \end{equation}
where $\mu$ and $\sigma$ are the mean and standard deviation of the dataset's input.
We can then plot the hyperbolic tangent correspnoding to those weights providing the lowest cost function value during the run, as we do below. The fit does indeed match the behavior of the dataset well and its linear decision boundary does indeed separate the two classes completely.

In discussing classification through the lens of logistic regression in Section 6.2, we saw how linear classification can be thought of as a particular instance of nonlinear regression. In particular how from this perspective we aim at fitting a curve (or surface in higher dimensions) that consists of a linear combination of our input shoved through the tanh function. For $N=1$ dimensional input this regression looks like
\begin{equation} \text{tanh}\left(w_0^{\,} + {x}_p {w}_{1}^{\,}\right) \approx y_p. \end{equation}
Here our model is the simple linear one
\begin{equation} \text{model}(x,\mathbf{w}) = w_0 +_{\,} x_{\,}w_1. \end{equation}
With classification this function defines the linear decision boundary - a single point in this instance - where $\text{model}(x,\mathbf{w}) = 0$. After tuning our weights properly by e.g., minimizing the softmax cost function, this decision boundary provides us with predicted labels for every possible input. In particular if $\text{model}(x,\mathbf{w}) > 0$ then $x$ assigned to $+1$ class, if $\text{model}(x,\mathbf{w}) < 0$ assigned to $-1$ class. This is illustrated in the Figure below.
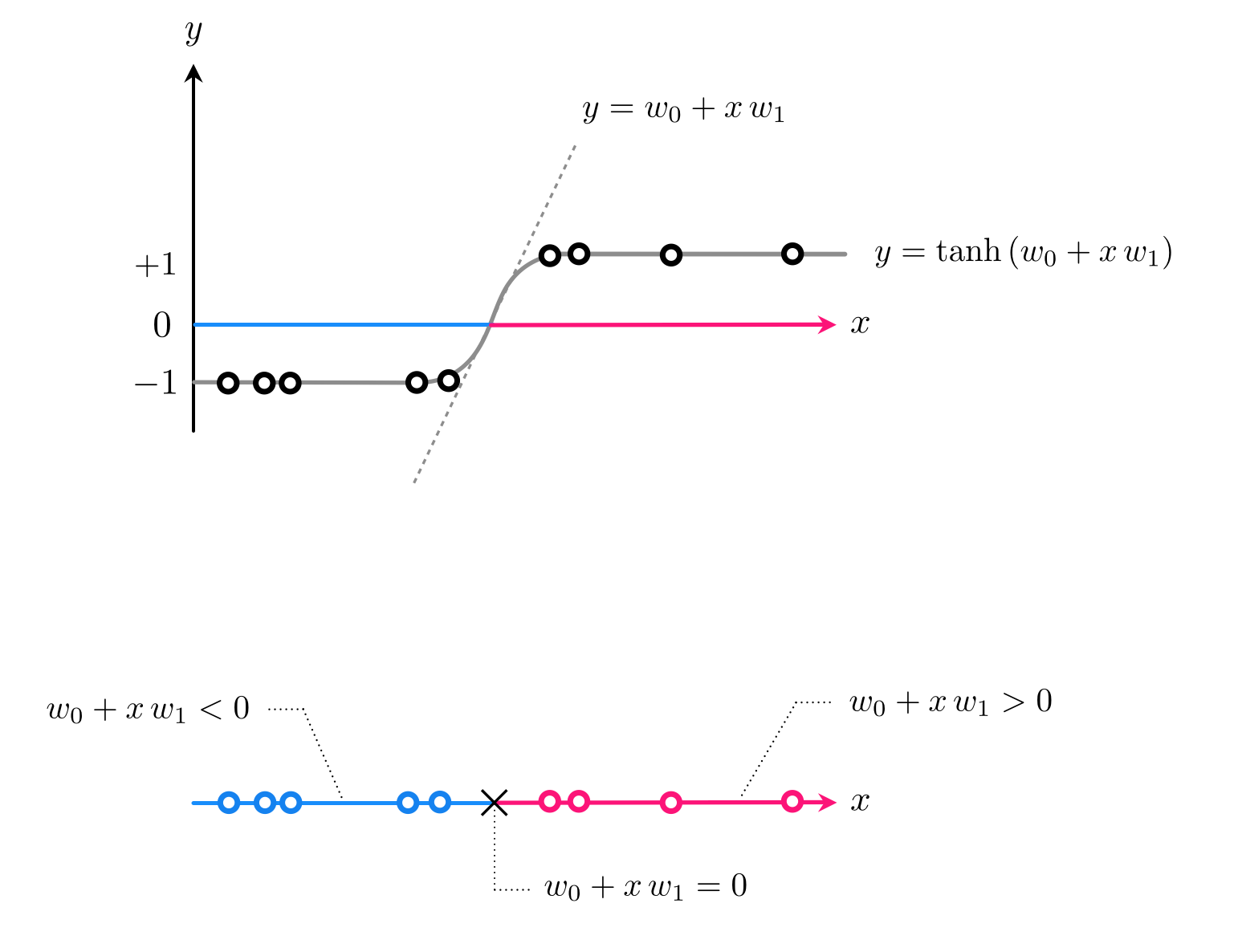
However a linear predictor - a linear decision boundary - is quite inflexible in general and fails to provide good separation even in the simple example below. Here we clearly need a model function that can cross the input space (the x axis) twice at points separated by a large distance - something a linear model can never do.

What sort of simple function crosses the horizontal axis twice? A quadratic function is a simple example. If adjusted to the right height a quadratic certainly can be made to cross the horizontal axis twice and - when shoved through a tanh - could indeed give us the sort of predictions we desire. This idea is drawn figuratively for a dataset like the one above in the Figure below, where a dataset like the one we are examinig is shown both from a regression perspective (top panel) and 'from above' where label values are represented by unique colors (bottom panel).
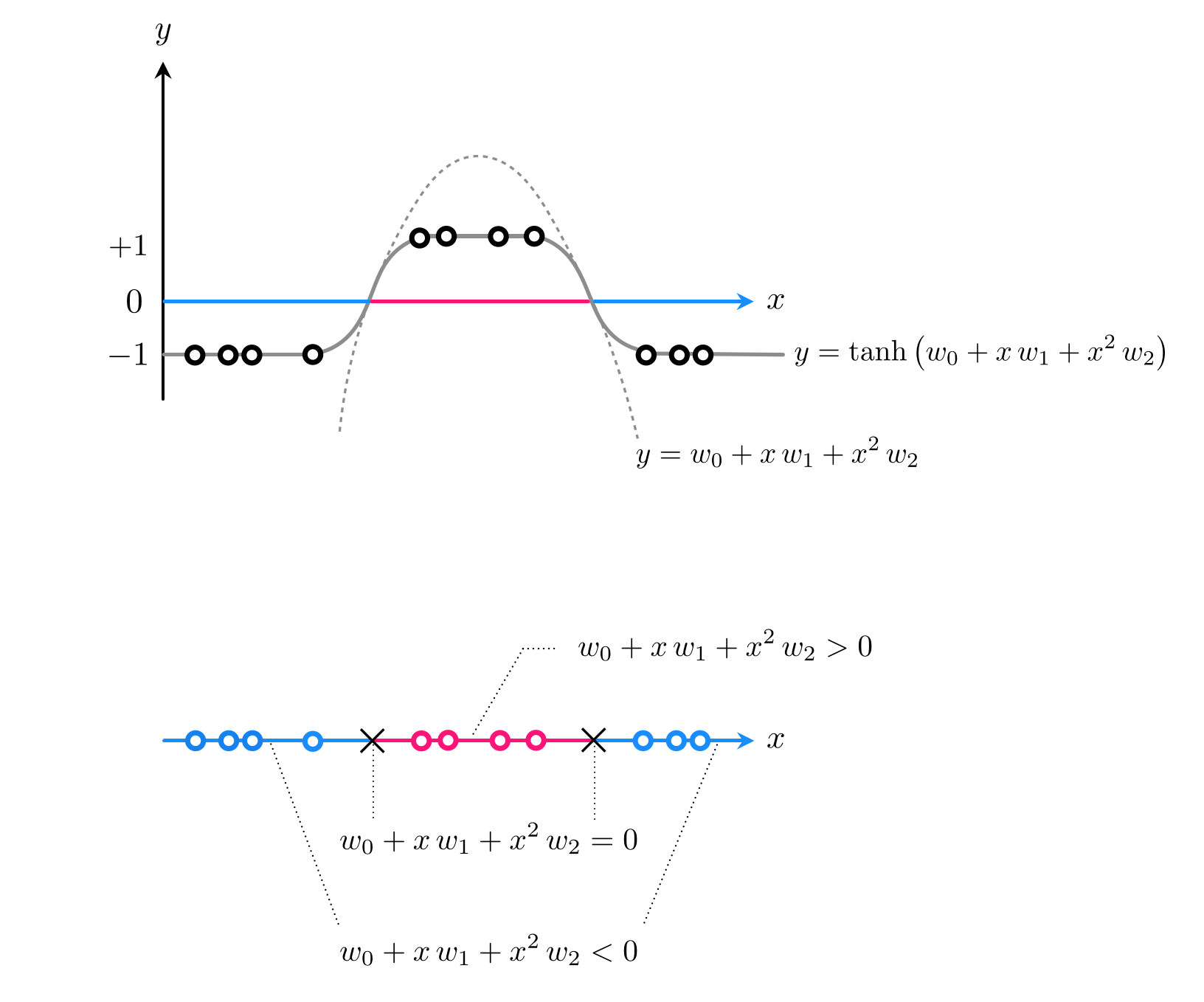
Using a generic quadratic function as our model takes the form
\begin{equation} \text{model}(x,\mathbf{w}) = w_0 + xw_1 + x^2w_2. \end{equation}
Notice here how we have two unparameterized feature transformations: the identity $f_1(x) = x$ and the quadratic term $f_2(x) = x^2$, and so we may write the above equivalently as
\begin{equation} \text{model}(x,\Theta) = w_0 + f_1(x)\,w_1 + f_2(x)\,w_2 \end{equation}
where here the weight set $\Theta = \left\{\mathbf{w}\right\}$.
We will then tune our parameters via applying gradient descent to minimize the Softmax cost, and to speed up its convergence we will apply standard normalization (as discussed in Section 9.3) to the input of the data. With our weights tuned and our predictor trained we can then plot the resulting fit / separation. In the left panel we show the original dataset - from the regression perspective- along with the nonlinear fit provided by our nonlinear logistic regressor $\text{tanh}\left(\text{model}\left(x, \mathbf{w}\right)\right) = y$. In the right panel we show the same dataset only in the transformed feature space defined by our two features. Here a datapoint that originally had input $x_p$ now has input $\left(f_1\left(x_p\right)\,,(f_2\left(x_p\right)\right)$. In this space the separation / decision boundary is linear.

What we see with this example - a nonlinear decision boundary in the original space being simultaneously linear in the transformed feature space - always happens in practice if we have chosen our features well (i.e., as to provide a good nonlinear decision boundary in the original space).
Also notice here that since we have used two features our feature space is one dimension larger than the original space. As was the case with regression this is true more generally speaking: the more feature transforms we use the higher the up we go in terms of the dimensions of our transformed feature space / linear separation! In general if our original input has dimension $N$ - and is written as $\mathbf{x}$ - and we use a model function that employs $B$ nonlinear (parameterized or unparameterized) feature transformations then our original space has $N$ dimensional input, while our transformed feature space is $B$ dimensional. Note here that the set of all weights $\omega$ contains not only the weights $w_1,\,w_2,...,w_B$ from the linear combination, but also any features's internal parameters as well.
Let us examine the following $N=2$ input dataset below, visualized the regression perspective (left panel) and 'from above' (right panel).

Visually examining the dataset it appears that some sort of elliptical decision boundary centered at the origin might do a fine job of classification. Thus we set our model function to the general parameterized form of such an ellipse
\begin{equation} \text{model}(\mathbf{x},\Theta) = w_0^{\,} + x_1^2w_1^{\,} + x_2^2w_2^{\,}. \end{equation}
Parsing this formula ,we can see that we have used two feature transformations $f_1(\mathbf{x})=x_1^2$, $f_2(\mathbf{x}) = x_2^2$, and the parameter set $\Theta = \left\{w_0,\,w_1,\,w_2\right\}$.
With our weights tuned - by minimizing the Softmax cost via gradient descent - we can plot the data in its original space (left panels) - along with the nonlinear decision boundary provided by the trained predictor - and in the transformed feature space (right panels) - where the corresponding decision boundary is linear. In each panel we color a region of space by what class our predictor assigns it post training. Indeed our presumption of an elliptical boundary seems like a good one here - as our classification results are quite good.

Python¶The general nonlinear model in equation (4) above can be implemented precisely as described in Section 10.2.4. since - indeed - it is the same general nonlinear model we use with nonlinear regression. Therefore, just as with regression, the we need not alter the implementation of any two-class classification cost function introduced in Chapter 6 to perform nonlinear classification: all we need to do is properly define our nonlinear transformation(s) in Python (if we wish to use an automatic differentiator then these should be expressed using autograd's numpy wrapper).
For example, one way to implement the feature transformation used in Example 3 is shown below.
# feature transformation shown in Example 3
def feature_transforms(x):
# calculate feature transform
f = x**2
return f